❗️블로그 옮김: https://www.taemobang.com
방태모
안녕하세요, 제 블로그에 오신 것을 환영합니다. 통계학을 전공으로 학부, 석사를 졸업했습니다. 현재는 가천대 길병원 G-ABC에서 Data Science를 하고있습니다. 통계학, 시계열, 통계적학습과 기계
www.taemobang.com
로지스틱 회귀모형(Logistic regression model)은 $x$에 관한 선형 함수(linear function)를 통해 관측치가 class = $K$에 속할 사후 확률(posterior probabilities)을 모델링한다. 그래서 로지스틱 회귀모형은 분류 문제에 적절하며, 분류기 중에서도 선형 분류기(linear classifier)에 해당한다. class가 $K$개인 반응 변수 $Y$의 로지스틱 회귀모형 모수 추정에는 $(K-1)$개의 선형 함수가 필요한데, 이를 특히 "Baseline-category logit regression"이라 칭하기도 한다. 여기서는 설명의 편의를 위해 반응 변수 $Y$의 형태를 0 또는 1 값만을 취하는 이진 변수(binary variable)로 가정한다. 이진 변수의 경우 1개의 선형 함수만 필요로 된다. 이는 Biostatistical application에 널리 쓰이는데, 예를 들면, 심장병 여부나 환자의 사망 여부와 같은 것들이 반응 변수 $Y$일 때를 말한다. 이제 이러한 로지스틱 회귀모형의 모형화 과정과 추정에 대해 알아보자.
모형화(modeling)
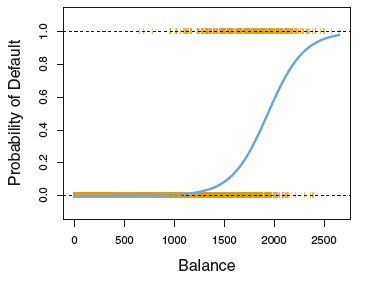
로지스틱 회귀모형의 모형화 과정을 설명하기 전에, 먼저 어떤 관측치가 class=1에 속할 사후 확률을 추정하고자 할 때 선형 회귀모형(Linear regression model)을 쓰지 못하는 이유에 대해 알아보자.
$\pi = Pr(Y=1 | X=x) = \beta_0 + \beta_1x $
$\pi$는 확률로 0과 1사이의 값인데, 이를 위 식처럼 선형 회귀모형으로 모델링할 경우 확률의 상한과 하한을 벗어나게 되는 문제가 발생한다. 다음 그림에 이 문제가 잘 드러난다.

이 외에도, $\pi$에 대해 OLS 추정을 수행할 수 없는 이유는 하나 더 존재한다. 반응 변수 $Y$는 베르누이(Bernoulli) 확률변수로 분산이 $\pi$의 함수가 되는데:
$Y \sim Ber(\pi)$, $E(Y) = \pi$, $Var(Y) = \pi(1-\pi)$
이러한 경우 $\pi$는 $X$와 $\beta$에 관한 함수로, 등분산(equal variance; homoscedasticity)의 가정이 성립되지 않기 때문이다.
그래서 우리는 확률 $\pi$와 $X$ 사이의 관계를 적절하게 설명해줄 수 있는 함수가 필요하다. 이 둘의 관계는 흔히 로지스틱 분포(Logistic distribution)의 cdf(cumulative distribution function)로 표현된다. 로지스틱 분포의 cdf를 로지스틱 함수(Logistic function)라고 칭한다.

위와 같이 S-형태의 곡선을 그리는 함수로, 수식은 다음과 같이 정의된다:
$f(x) = \frac{1}{1+e^{-x}} = \frac{e^x}{1+e^x}$
머신러닝(Machine Learning)에서는 흔히 "시그모이드 함수(Sigmoid function)"라고 부르는 함수다. 확률 $\pi$를 위 함수에 대해 모델링할 경우, $X$가 증가함에 따라 처음에는 서서히 증가하다가 급격히 증가하고, 마지막에는 값이 안정화되지만 1을 넘지 않는다. 직관적으로도 타당해 보인다. 이제 앞서 $\pi$에 대해 선형 회귀 모델링을 적용한 식에 로지스틱 함수의 cdf를 걸어주자. 이를 통해 $\pi$는 0과 1 사이 값만을 가질 수 있게 된다:
$\pi = Pr(Y=1 | X=x) = \frac{e^{\beta_0 + \beta_1x}}{1 + e^{\beta_0 + \beta_1x}}$
위 식을 "로지스틱 회귀모형(logistic regression model)"라고 한다. S-곡선을 생성하는 다른 확률 모형으로 정규분포의 cdf를 사용할 수도 있는데, 이는 "프로빗(probit) 모형"이라고 한다. 이 글에서는 프로빗 모형에 대해 다루지 않는다. 왜냐하면 로지스틱 모형이 프로빗 모형에 비해 더 간단하고 우수하기 때문이다. 이 로지스틱 모형은 여러 개의 설명변수가 있는 형태로 바로 일반화시킬 수 있다:
$\pi = Pr(Y=1|X_1 = x_1, \cdots, X_p = x_p) = \frac{e^{\boldsymbol{\beta}^T x_i}}{1 + e^{\boldsymbol{\beta}^T x_i}} = \frac{e^{\beta_0 + \beta_1x_1 + \cdots + \beta_px_p}}{1 + e^{\beta_0 + \beta_1x_1+ \cdots + \beta_px_p}}$
아직 $x$에 대해 비선형이며, 로짓 변환(logit transformation)에 의해 선형화시킬 수 있다. 즉, 우리는 $\pi$의 변환된 값을 가지고 작업한다. 여기서 변환된 값이란 오즈(Odds)를 말하는데, 오즈는 성공과 실패의 비를 말한다. 즉, $\pi$가 어떤 사건(event)의 발생 확률이라면 그 사건의 오즈는 $\pi/(1-\pi)$에 해당한다. 로짓 변환은 확률의 오즈에 자연로그 함수를 취하는 것을 말한다:
$1 - \pi = Pr(Y=0|X_1 = x_1, \cdots, X_p = x_p) = \frac{1}{1 + e^{\beta_0 + \beta_1x_1 + \cdots + \beta_p}}$
$\frac{\pi}{(1-\pi)} = e^{\beta_0 + \beta_1x_1 + \cdots + \beta_px_p }$
$g(x_1, \cdots, x_p) = ln(\frac{\pi}{1-\pi}) = \beta_0 + \beta_1x_1 + \cdots + \beta_px_p$
이렇게 $\pi$에 대해 로짓 변환을 가해주면 $x$에 대해 선형화가 되며, $ln(\frac{\pi}{1-\pi})$를 로그 오즈(log-odds) 또는 로짓(logit)이라 하며, 우리는 "로지스틱 회귀모형은 $X$에 대해 선형인 로짓을 갖는다."라고 표현할 수 있다. 로지스틱 회귀모형이 선형 분류기인 이유는 여기서 비롯되는데, 자세한 사항은 다음의 추정에서 설명한다.
다음의 추정 내용에서는 로짓이 가질 수 있는 값의 범위를 알아두어야 한다. $\pi$가 0과 1 사이의 값을 가지므로, 오즈의 범위는 [$0$, $\infty$]이 되며, 이에 자연로그를 취한 로짓의 범위는 [$-\infty$, $\infty$]가 된다.
로지스틱 회귀모형의 적합
1 MLE(Maximum likelihood estimation)를 사용하는 이유
로지스틱 회귀모형의 회귀 계수의 추정은 LSE(Least squares estimation)가 아닌 MLE를 기반으로 이루어진다. 회귀계수 추정에 LSE를 사용하는 것이 적절하지 않은 이유는 그림을 그려서 생각해보면 알 수 있다.

먼저 반응 변수 $Y$의 실제 값은 왼쪽 그림에서 확인할 수 있듯이 0 또는 1로 존재한다. 이를 기반으로 로짓의 값을 계산해보면 결국 오른쪽 그림처럼 1에 속하면 $\infty$, 0에 속하면 $-\infty$이 된다. 이는 곧 실제 값과 추정 값의 잔차도 늘 무한대임을 의미하며, 이러한 상황에 회귀계수 추정에 LSE를 사용하는 것은 직관적으로도 옳지 않다(로지스틱 회귀모형의 로짓에 오차항을 포함시키지 않는 이유도 이러한 이유에서라고 생각한다).
2 MLE에서 사용하는 아이디어
로지스틱 회귀모형에서의 MLE에 깔려있는 기본적인 아이디어는, S-곡선 형태의 분포를 띠는 $\pi$를 likelihood로 사용하여 주어진 데이터가 관측될 확률을 최대로 해주는 $\boldsymbol{\beta}$를 추정하는 것이다. 그럼 이렇게 S-곡선의 형태인 $\pi$를 추정하는 것인데 왜 로지스틱 회귀모형을 선형 분류기라고 하는 것일까? 그 이유는 모형화 과정에서 살펴봤듯이 likelihood의 계산에 필요한 S-곡선 $\pi$의 추정은 로짓을 기반으로 이루어지며, 이 로짓은 $X$에 대해 선형이기 때문이다. 즉, 근본적인 회귀 계수의 추정은 $X$에 대해 선형인 로짓에 의해 이루어지며, 이때 추정된 로짓은 likelihood를 최대로 해주는 직선에 해당한다. 그래서, 로지스틱 회귀모형의 회귀계수 추정은 $y$축이 $log(Odds)$인 것을 제외하면 선형 회귀모형(linear regression model)과 정확하게 일치한다.
3 회귀계수 추정의 자세한 과정
기본적으로 로지스틱 회귀모형의 가능도 함수(likelihood function)는 닫힌 형태(closed form)가 아니기 때문에, 수치해석적 접근을 통해 반복적으로(iteratively) $\hat{\boldsymbol{\beta}}$를 구해야 한다. 우리가 최대화해야 하는 가능도함수를 수식으로 정의하기 전에, 앞서 얘기한 MLE의 아이디어를 기반으로 해를 구하는 반복적인 과정을 직관으로 써보면 다음과 같다:
① $\hat{\boldsymbol{\beta}}$의 적절한 초깃값을 선택하여 로짓 계산.
② 로짓 값을 $\pi$에 대입하여 log-likelihood 계산.
③ log-likelihood를 증가시킬 수 있는 방향으로 $\hat{\boldsymbol{\beta}}$을 업데이트하여, 최적의 값을 찾는다.
likelihood의 계산에서는 log를 안 취해도 되지만, 보통 계산의 편의를 위해 log-likelihood를 선호하며 log를 취해도 가능도 함수를 최대화하는 $\hat{\boldsymbol{\beta}}$ 값은 바뀌지 않는다. 즉, 위 과정의 반복을 통해 관측된 데이터를 기반으로 최적의 분류를 수행할 수 있는 로지스틱 회귀모형을 적합시킬 수 있다.
이제 수식을 통해 자세하게 알아보자. 최대화해야 하는 로지스틱 회귀모형의 가능도함수를 유도한다. 이제부터는 확률 표본 하나하나의 의미를 추가하기 위해 아래 첨자 $i$를 추가한다. 먼저, 확률 표본(random sample) $y_i$는 이진 변수로 베르누이 분포(Bernoulli distribution)를 따르게 되므로 다음과 같은 pdf를 가진다.
$f(y_i ; \pi_i) = \pi_i^{y_i}(1-\pi_i)^{1-y_i}$
이때 우리에게 n개 확률 표본(i.i.d 가정을 만족하는 데이터)이 주어졌다고 하면, 가능도함수는 다음과 같이 모든 확률 표본들의 pdf를 곱한 형태가 된다.
$L(\boldsymbol{\beta} | X, y) = f(y_1; \pi_1)\cdot\; \cdots \; \cdot f(y_n; \pi_n) = \prod_{i=1}^n \pi_i^{y_i}(1-\pi_i)^{1-y_i}$
이때 가능도 함수에서 고려하는 것으로 관측 데이터 $X$와 모수 $\boldsymbol{\beta}$가 나타나지만, 식에 암묵적으로(implicitly) 나타나지 않게 되는 이유는 $X$와 $\boldsymbol{\beta}$의 계산에 의존하는 $\pi_i$ 때문이다. 마지막으로 계산의 편의를 위해 log-likelihood를 고려하면:
$l(\boldsymbol{\beta} | X, y) = \sum_{i=1}^{n} \left \{y_i log\pi_i + (1-y_i)log(1-\pi_i) \right \}$
로지스틱 회귀모형에서 $\boldsymbol{\beta}$의 추정을 위해 최대화해야 하는 로그 가능도 함수는 위와 같은 과정을 거쳐 정리된다. 참고로 로그 가능도함수의 최대화를 손실 함수(loss function)를 최소화하는 문제로 바꾸기 위해 (-)를 취하여 음의 로그 가능도함수(negative log-likelihood function)를 이용하기도 한다. 로그 가능도함수의 최대화를 위해, 미분을 하기 전에 위 식을 조금 정리한다. 이때 $\boldsymbol{\beta}$는 절편을 포함한 회귀계수 벡터이며, $x_i$는 intercept를 고려하여 상수 1을 포함하는 input 벡터에 해당한다:
$l(\boldsymbol{\beta} | X, y) = \sum \left \{y_ilog\pi_i - y_i log(1-\pi_i) + log(1-\pi_i) \right \} \\
\;\;\;\;\;\;\;\;\;\;\;\;\;\; = \sum \left \{ y_ilog \frac{\pi_i}{1-\pi_i} + log \frac{1}{1+e^{\boldsymbol{\beta}^Tx_i}} \right \} \\
\;\;\;\;\;\;\;\;\;\;\;\;\;\; = \sum \left \{ y_i\boldsymbol{\beta}^Tx_i - log(1+e^{\boldsymbol{\beta}^T x_i}) \right \}$
이제 로그 가능도함수의 최대화를 위해 $\boldsymbol{\beta}$에 대한 1차 미분(derivatives)을 0으로 놓는다. 이를 score eqautions이라 한다.
$\frac{\partial l(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}} = \sum x_i(y_i - \pi_i) = 0$ $\cdots$ (3.1)
(3.1)을 풀기 위해서는 Newton-Raphson 알고리즘이 필요하므로, 2차 미분(second-derivative)을 수행한다.
$\frac{\partial^2 l(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}\partial \boldsymbol{\beta}^T} = \frac{\partial}{\partial \boldsymbol{\beta}^T} \sum(x_iy_i - x_i\frac{e^{\boldsymbol{\beta}^Tx_i}}{1+e^{\boldsymbol{\beta}^Tx_i}}) \\ \;\;\;\;\;\;\;\;\; = -\sum (x_i x_i^T \frac{e^{\boldsymbol{\beta}^Tx_i}}{(1 + e^{\boldsymbol{\beta}^Tx_i})^2}) \\ \;\;\;\;\;\;\;\;\; = -\sum (x_i x_i^T \frac{e^{\boldsymbol{\beta}^Tx_i}}{1+e^{\boldsymbol{\beta}^Tx_i}}\frac{1}{1+e^{\boldsymbol{\beta}^Tx_i}}) \\ \;\;\;\;\;\;\;\;\; = -\sum x_i x_i^T \pi_i(1-\pi_i)$ $ \;\;\;\;\;\;\;\;\;\; \cdots$ (3.2)
이제 준비가 끝났다. Newton-Raphson 알고리즘은 다음과 같은 식으로 해를 반복적으로 추정한다:
$\boldsymbol{\beta}^{new} = \boldsymbol{\beta}^{old} - (\frac{\partial^2 l(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}\partial \boldsymbol{\beta}^T})^{-1}\frac{\partial l(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}}$ , where the derivatives are evaluated at $\boldsymbol{\beta}^{old}$ $\cdots$ (Newton step)
표현의 편의를 위해 score equations (3.1)과 2차 미분계수 (3.2)를 matrix notation으로 쓴다:
$\boldsymbol{y}$ = $y_i$를 성분으로 갖는 벡터
$X$ = $x_i$를 행으로 갖는 $N \times (p+1)$ 행렬
$\boldsymbol{p}$ = $\boldsymbol{\beta}^{old}$를 기반으로 계산한 $\pi_i$를 성분으로 갖는 벡터
$\boldsymbol{W}$ = $\boldsymbol{\beta}^{old}$를 기반으로 계산한 $\pi_i(1-\pi_i)$를 성분으로 갖는 $N \times N$ 대각 행렬
그럼 이제 (3.1)과 (3.2)은 다음과 같이 표현된다:
$\frac{\partial l(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}} = X^T(\boldsymbol{y} - \boldsymbol{p})$
$\frac{\partial^2 l(\boldsymbol{\beta})}{\partial \boldsymbol{\beta}\partial \boldsymbol{\beta}^T} = -X^T\boldsymbol{W}X$
Newton step을 정리하면:
$\boldsymbol{\beta}^{new} = \boldsymbol{\beta}^{old} + (X^T\boldsymbol{W}X)^{-1}X^T(\boldsymbol{y} - \boldsymbol{p}) \\ \;\;\;\;\;\;\; = (X^T\boldsymbol{W}X)^{-1}X^T\boldsymbol{W}(X\boldsymbol{\beta}^{old} + \boldsymbol{W}^{-1}(\boldsymbol{y} - \boldsymbol{p})) \\ \;\;\;\;\;\;\; = (X^T \boldsymbol{W} X)^{-1}X\boldsymbol{W}z$
$z$를 이용해 Newton step의 식을 weighted least squares step으로 재표현(re-expressed)했으며, $z$는 조정된 반응 변수(adjusted response)라고 불리기도 한다.
$z = X\boldsymbol{\beta}^{old} + \boldsymbol{W}^{-1}(\boldsymbol{y} - \boldsymbol{p})$
즉, Newton Raphson 알고리즘을 통해 해를 구하는 것은 각 반복에서 $\boldsymbol{p}$와 $\boldsymbol{W}$, $z$를 갱신하며 weighted least squares 문제를 푸는 것과 같다고 할 수 있다. 그래서 이 알고리즘을 IRLS(Iteratively reweighted least squares)라 표현하기도 한다:
$\boldsymbol{\beta}^{new} \leftarrow arg \; \underset{\boldsymbol{\beta}}{min}(z - X\boldsymbol{\beta})^T \boldsymbol{W}(z-X\boldsymbol{\beta})$
반복적인 과정에서 초깃값으로 $\boldsymbol{\beta} = 0$은 수렴을 보장해주진 않지만 좋은 초깃값이 될 수 있다. 일반적으로 로그 가능도함수는 concave의 형태이기 때문에 보통 수렴하지만, 오버슈팅(overshooting : step size가 지나치게 커서 수렴하지 못하는 경우)이 발생할 수도 있다. 오버슈팅이 발생하는 경우는 드물긴 하지만, 발생하는 경우 step size를 반으로 줄이면 수렴을 보장받을 수 있게 된다. 위 식은 결국 다음과 같이 쓸 수도 있는데, 이를 "이차 추정(quadratic approximation)"이라 표현한다.
$L(\boldsymbol{\beta}) \approx (z - X\boldsymbol{\beta})^T \boldsymbol{W}(z-X\boldsymbol{\beta})$
Newton Raphson 알고리즘은 다범주($K \geq 3$)의 경우에도 IRLS 알고리즘으로 표현되는데, non-diagonal Weight matrix $\boldsymbol{W}$를 갖게되어 계산에 어려움을 겪는다. 그래서 이때는 로그 가능도함수를 효율적으로 최대화에 하기 위해 좌표 하강법(coordinate-descent methods)을 사용할 수도 있다.
Newton Raphson 알고리즘을 IRLS 알고리즘으로 재표현해나가는 자세한 과정은 The Elements of Statistical Learning(2017)의 Logistic regression을 참고했다. 혹시 이해가 안 되거나, 내 설명이 부족하다면 걸어놓은 링크를 참고하길 바란다.
회귀계수 해석
로지스틱 회귀모형은 로짓 변환을 통해 $X$에 대해 선형화를 하여 회귀계수를 추정하는 것이므로 해석에는 주의가 필요하다. 예를 들어, 종양의 크기(mm)에 따른 심장병 여부의 확률에 대해 로지스틱 회귀모형을 적합한 결과가 다음과 같다고 하자.
$ln\frac{\pi_i}{(1-\pi_i)} = 0.01 + 0.8*x_i$, where $x_i$ is the size of tumor
이때 $\hat{\beta}_1 = 0.8$은, 종양의 크기가 한 단위(1mm) 증가하면 환자가 심장병에 걸릴 오즈는 $e^{0.8} = 2.23$배 증가함을 의미한다.
맺음말
Logistic regression에 대한 개념, 수학적 백그라운드에 대해 자세하게 설명해보았다. 혹시, 이 글의 설명만으로 Logistic regression에 대한 직관적인 이해가 부족하다는 생각이 들면 Youtube <Statquest> 채널의 Logistic regression에 관한 시리즈를 꼭 들어보길 권한다.
참고 자료 및 사이트
James, Gareth, et al. An Introduction to Statistical Learning. Springer. 2013
Hastie, Trevor, et al. The Elements of Statistical Learning. 2017
Logistic Regression Details Pt 2: Maximum Likelihood (Statquest) on Youtube
김기영, 전명식, 강현철, 이성건 (2015). 예제를 통한 회귀분석. 자유아카데미
'Machine&Statistical Learning' 카테고리의 다른 글
| GLMs: Generalized Linear Models (1) | 2020.06.06 |
|---|---|
| Ensemble methods (0) | 2020.02.12 |


댓글