❗️블로그 옮김: https://www.taemobang.com
방태모
안녕하세요, 제 블로그에 오신 것을 환영합니다. 통계학을 전공으로 학부, 석사를 졸업했습니다. 현재는 가천대 길병원 G-ABC에서 Data Science를 하고있습니다. 통계학, 시계열, 통계적학습과 기계
www.taemobang.com
📝 prerequisite
이번 글에서는 딥러닝뿐만이 아닌 보다 더 큰 집합이라 할 수 있는 기계학습(machine learning, ML), 인공지능(artificial intelligence, AI)에 대한 연구배경과 전반적 개념에 대한 소개를 하려고 합니다. 먼저, 딥러닝(deep learning, DL)이라는 분야는 비교적 최근에 대중들의 관심을 받은 기술입니다. 아울러, 딥러닝을 포함하는 가장 큰 집합이라 할 수 있는 인공지능은 현재 실제 문제에 많이 적용되고 있으며 지금도 활발한 연구 주제들이 오가고 있습니다. 매스컴에서는 딥러닝이 마치 최근에 개발된 신기술처럼 보도되는 경향이 있지만, 사실 그 역사는 상당히 길다고 할 수 있습니다. 예로부터 사람들이 바래왔던 인공지능의 역할은 단순 반복 작업의 자동화, 음성 또는 이미지 인식, 의학적 진단 등이라 할 수 있으며, 오늘날 AI 영역이 직면하는 주 도전과제는 인간이 쉽게 수행하는 일(자동적으로 느껴지는 직관적인 문제들, e.g. 음성 인식, 사진의 얼굴 인식 등)을 해결할 수 있음을 증명하는 것입니다. 이 게시판에서 글을 쓰며 참고할 책인 Deep learning(Goodfellow et al. 2016)은 이러한 직관적 판단이 필요한 문제들에 대한 해결책을 담고있다고 할 수 있겠습니다.

딥러닝 기술에 대해 러프하게 말해보면, 컴퓨터는 딥러닝을 통해 직관적 판단이 필요한 문제를 간단한 개념을 층별로 쌓아 계층적 관점에서 학습(또는 훈련)하여 풀어냅니다. 딥러닝에서는 각 층에서 아주 간단한 활성함수(activation function)가 정의되는 은닉층(hidden layer)을 쌓아나갑니다. 각 층은 간단한 개념이지만 이러한 간단한 개념들이 서로 관련지어지면서 쌓여감에 따라 딥러닝은 복잡한 문제를 풀 수 있게 되죠.
아이러니하게도, 인간이 정신적으로 어려워하는 일들은 오히려 컴퓨터가 수행하기 가장 쉬운 것들에 해당합니다. 예를 들어, 체스나 바둑같은 것이라 할 수있겠죠. 알다시피 컴퓨터는 오랜 시간 동안 최고의 체스 선수들을 상대로 승리해왔지만 최근에서야 객체 또는 음성을 인식하는 인간의 평균적인 능력을 맞출 수 있게 됐습니다. 문제는, 이렇게 체스 선수나 바둑 기사들을 이기는 행위는 우리 실생활에 실제적으로 가져다주는 것이 없다는 점입니다. 객체 또는 음성 인식과 같은 행위를 컴퓨터로 풀어낼 없었던 이유는 매우 주관적이고 직관적이라 이를 형식적으로 표현하는 것이 매우 어려웠기 때문입니다. 이러한 행위는 informal knowledge에 해당하며, 컴퓨터에게 이를 습득시키는 것이 인공지능에서의 중요한 도전과제였습니다.
과거 몇몇 인공지능 프로젝트들은 형식적인 컴퓨터 언어를 통해 hard-coded knowledge를 추구했습니다. hard-coded knowledge는 컴퓨터가 논리적 추론 규칙(logical inference rules)을 사용하는 형식적인 언어들의 명시를 통해 자동적으로 사고하는 방식을 말하며, 이러한 접근 방식을 우리는 인공지능으로의 "knowledge base approach"라고 합니다. 결과론적으로, 이러한 접근방식을 사용하는 프로젝트들은 모두 큰 성공을 거두지 못했습니다. 이렇게 knowledge base approach에서 실패를 겪은 경험은, 연구자들에게 원자료로 부터 패턴을 추출함으로써 인공지능이 자신들만의 knowledge를 습득할 수 있는 능력이 필요함을 제시해주었습니다. 이러한 능력을 우리는 "기계학습"이라 칭합니다. 바로 이 기계학습으로의 접근이 컴퓨터가 실제 세계의 knowledge와 관련된 문제를 해결하는 것, 그리고 주관적 판단이 필요한 결정을 내리는 것을 가능하게 해주었다고 할 수 있죠. 예를 들면, 범주형 자료에 대한 회귀분석 모델이라고 할 수 있는 로지스틱 회귀모형(logistic regression)은 간단한 기계학습 알고리즘이라고도 할 수 있으며, 이는 제왕절개 수술의 권고 여부를 결정할 수 있게해주었습니다. 그리고, 아주 간단한 분류모형이라 할 수 있는 나이브 베이즈 모형(naive bayes)은 스팸메일을 분류할 수 있게 해주었죠.
이러한 간단한 기계학습 알고리즘들의 성능은 학습에 주어진 자료의 대표성(representation)에 크게 의존합니다. 예를 들면 로지스틱 회귀모형이 제왕절개 수술 권고여부의 결정에 사용될 때, 이 인공지능 시스템이 환자를 직접 검사하진 않습니다. 대신에 의사가 이 시스템에 제왕절개 수술 권고여부의 결정이 필요한 환자의 자궁 상처 여부 등과 같은 수술 권고와 관련된 정보($X$)들을 알려줍니다. 환자의 대표성에 포함되는 이러한 정보의 조각들을 "특성(feature)1"이라고 하며, 로지스틱 회귀모형은 환자들의 이러한 각 특성이 다양한 결과들과 얼마나 연관이 있는지를 학습합니다.
대표성에 대한 의존은 기계학습 분야뿐만이 아닌, 사실 우리의 일상을 통틀어서 나타나는 일반적인 현상입니다. 그래서 어떤 기계학습 알고리즘이 좋은 성능을 내기 위해서는 수행해야 할 일(task)에 맞는 특성들의 올바른 집합을 제공하는 것이 중요하다고 할 수 있겠습니다. 이는 기계학습 알고리즘뿐만이 아닌 통계적 예측모형2에도 당연히 적용되는 부분이죠. 그러나, 어떤 실제 문제를 해결하기 위한 자료가 주어졌을 때 어떤 특성이 모델링에 사용되어야 하는 지를 판단하는 것은 어렵습니다. 이 문제의 한 가지 해결책은 representation(대표성, i.e. $X$)을 $Y$(output)뿐만 아니라 representation 그 자체에도 맵핑하는 것을 찾아주는 기계학습 기법을 사용하는 것입니다. 우리는 이러한 접근을 "representation learning"이라고 하며, 이러한 알고리즘의 전형적인 예로는 주성분분석(principal component analysis, PCA), 오토인코더(autoencoder)가 있습니다. 모든 상황에서 그러하진 않겠지만, 학습된 representation은 인간이 손으로 고안하여 얻어진 것보다 훨씬 더 좋은 성능을 얻게 할 수 있습니다. 다만, 우리가 풀어야 할 본래의 문제를 푸는 것이 representation을 얻는 것만큼 어려울 때에는, represetation learning은 우리에게 그다지 도움이 되진 않을 것입니다.
앞서 딥러닝은 직관적 문제를 층별로 간단한 개념을 쌓아 계층적 관점에서 학습하여 풀어낸다고 하였습니다. 이를 앞서 사용한 representation이라는 단어로 설명하면, 딥러닝은 representation들을 더 간단한 representation으로 표현하는 관점으로서 representation learning이 갖는 문제점(representation을 얻는 것이 어려울 때)을 풀어낸다고 할 수 있습니다:
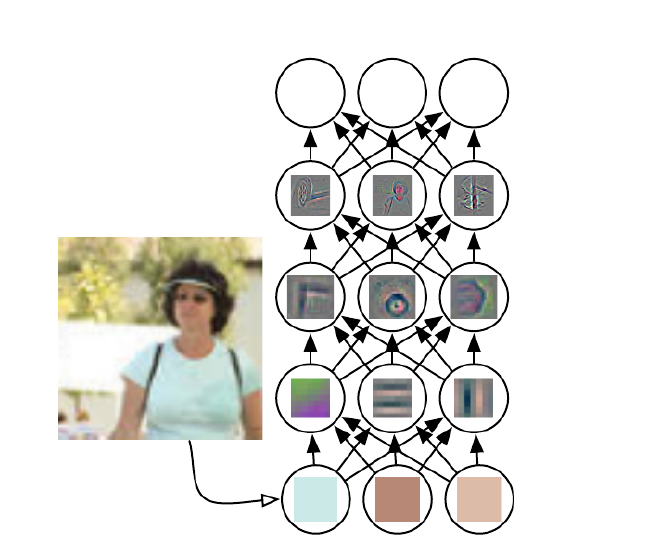
위 그림은 딥러닝 시스템이 더 간단한 개념들을 결합함으로써 한 사람이 찍힌 사진의 개념을 어떻게 표현할 수 있는지를 보여줍니다. 딥러닝 모형의 전형적인 예로는 "feedforward deep network", "다층 퍼셉트론(multilayer perceptron, MLP)"이 있으며, 두 용어 모두 동일한 모형을 지칭합니다. 다층 퍼셉트론을 단순히 말하면 $X$의 집합을 $Y$로 맵핑하는 수학적 함수라고 할 수 있습니다. 여러 층으로 겹쳐진 하나의 함수는 각 층의 간단한 함수들로 구성되며, 그에 따라 우리는 다른 수학적 함수를 각 층에서 적용하는 행위를 $X$에 새로운 representation을 제공하는 것으로 생각할 수 있는 것이죠.
앞서 기계학습, 딥러닝 기술의 모티베이션, 연구배경 등에 관해 설명하다보니 글이 길어졌는데, 이 글의 주제라 할 수 있는 "딥러닝"을 요약하자면 결국 딥러닝은 인공지능(AI)로의 접근이라 표현하고 싶습니다. 좀 더 구체적으로는 컴퓨터 시스템이 자료와 경험(experience)으로 개선해 나갈 수 있도록 해주는 기계학습 기술의 한 유형이라 할 수 있죠. 아울러, 기계학습만이 오직 복잡한 현실 세계에 작동할 수 있는 인공지능 시스템을 만드는 실행 가능한 접근이라고 이 책의 저자들은 주장합니다. 그중에서도 딥러닝은 (더 간단한 개념과 관련되어 정의되는 각 개념들의) 내포된 개념들의 계층(a nested hierarchy of concepts)을 사용함으로서, $X$들을 더욱 추상적인 representation으로 표현함으로써 현실 세계의 문제에 대한 강력한 힘과 유연성을 얻는 기계학습의 특별한 종류라고 표현합니다.

마지막으로 딥러닝의 역사적인 트렌드를 소개하고 글을 마치려고 합니다. 딥러닝이 역사가 긴 기술일 만큼, 그 맥락을 이해하면 딥러닝의 이해에 큰 도움이 됩니다. Deep learning(Goodfellow et al. 2016)에서는 딥러닝의 상세한 역사에 대해 제공한다기 보단 몇몇 중요한 트렌드를 언급해줍니다:
- 딥러닝은 길고 풍부한 역사를 가져왔으며, "딥러닝" 이라는 용어 이외에 다른 철학적 관점을 반영하는 많은 이름들이 있음
- 딥러닝의 인기는 역사적으로 봤을때 크게 들쑥날쑥함
- 딥러닝은 이용가능한 훈련 자료(training data)의 양이 많을수록 더 유용해짐
- 딥러닝을 위한 컴퓨터 인프라(하드웨어와 소프트웨어 둘 다)가 시간이 지남에 따라 발전했기 때문에, 그에따라 딥러닝 모형의 크기는 커질 수 있었음(deep).
- 딥러닝은 시간이 지남에 따라 점점 더 복잡해지는 문제들에 대한 정확도를 점차 높혀옴.
딥러닝이라는 기술은 특히 하나의 학문으로부터 발전한 것이라 보긴 힘들다고 생각합니다. 딥러닝은 지난 수십 년 동안 발전시켜온 인간의 뇌, 통계, 응용 수학 분야에 대한 지식을 끌어 모은 기계학습의 한 유형이라고 할 수 있습니다. 최근 몇 년 동안 딥러닝은 그 인기와 유용성에 엄청난 성장을 보였는데, 이는 주로 더 좋은 성능의 컴퓨터, 더 깊은 네트워크(모형의 깊이)를 훈련시키기 위한 더 큰 자료와 기술의 결과라 할 수 있습니다. 또한 Deep learning(Goodfellow et al. 2016)의 저자들은 앞으로의 몇년에도 딥러닝은 더 개선될 것이며 이를 새로운 한계로 가져다줄 도전 과제와 기회들로 가득차있을 것이라고 예측하고 있습니다. 실제로 2020년 현재에는 책이 출판된 2016년보다 딥러닝 분야에 상당히 비약적인 발전이 있었네요.😃
긴 글을 읽어주셔서 감사합니다. 이 글이 머신러닝, 딥러닝의 연구배경, 모티베이션 등에 대한 궁금증을 조금이나마 풀어주었으면 좋겠습니다.
참고 도서
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. Deep Learning. The MIT Press, 2016

댓글